obs-websocketというプラグインが必要です。
リリースページからwindows版の最新のzipファイルobs-websocket-
..*-Windows.zipをダウンロードし、中身をOBS-Studioをインストールしているフォルダに展開します。
例えばC:\Program Files (x86)\obs-studio です。
ちなみに2019/6/30時点の最新版は
obs-websocket-4.6.1-Windows.zip です。
展開したらOBS-Studioを再起動します。「ツール」→「WebSockets Server Settings」からプラグインの設定を行う。
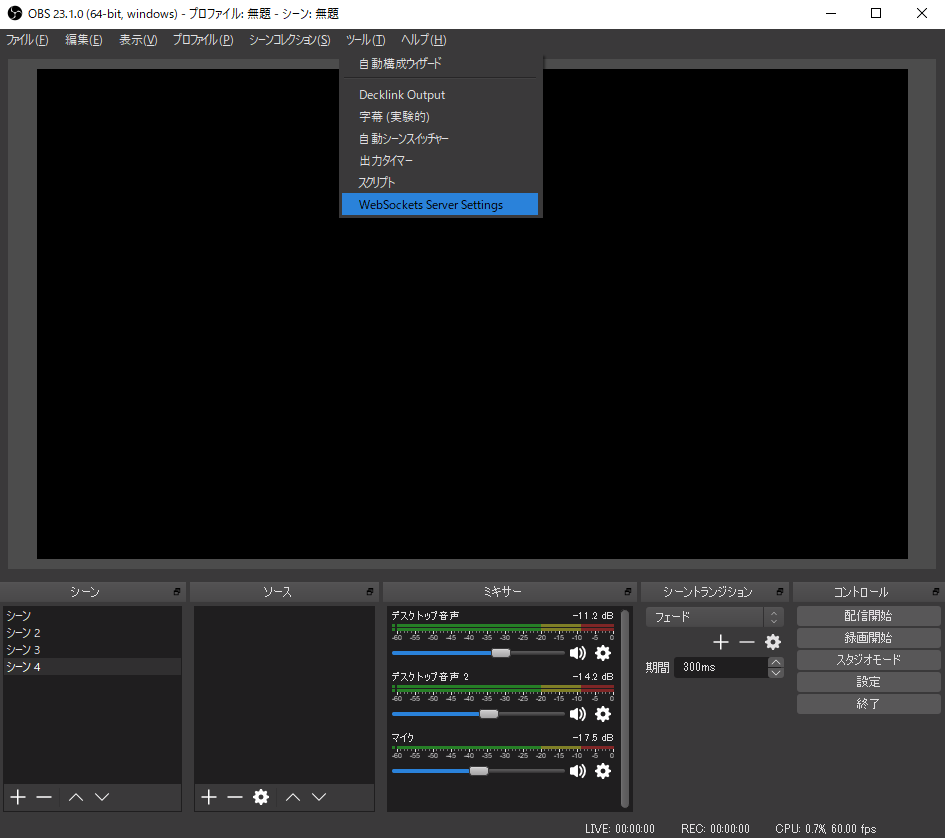
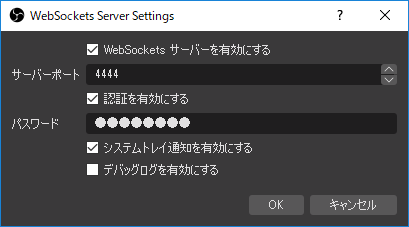
サーバーポートはデフォルトの「4444」。
「認証を有効にする」をオンにしてパスワードを「password」に設定する(これはさすがに後の更新で変更できるようにする予定)。
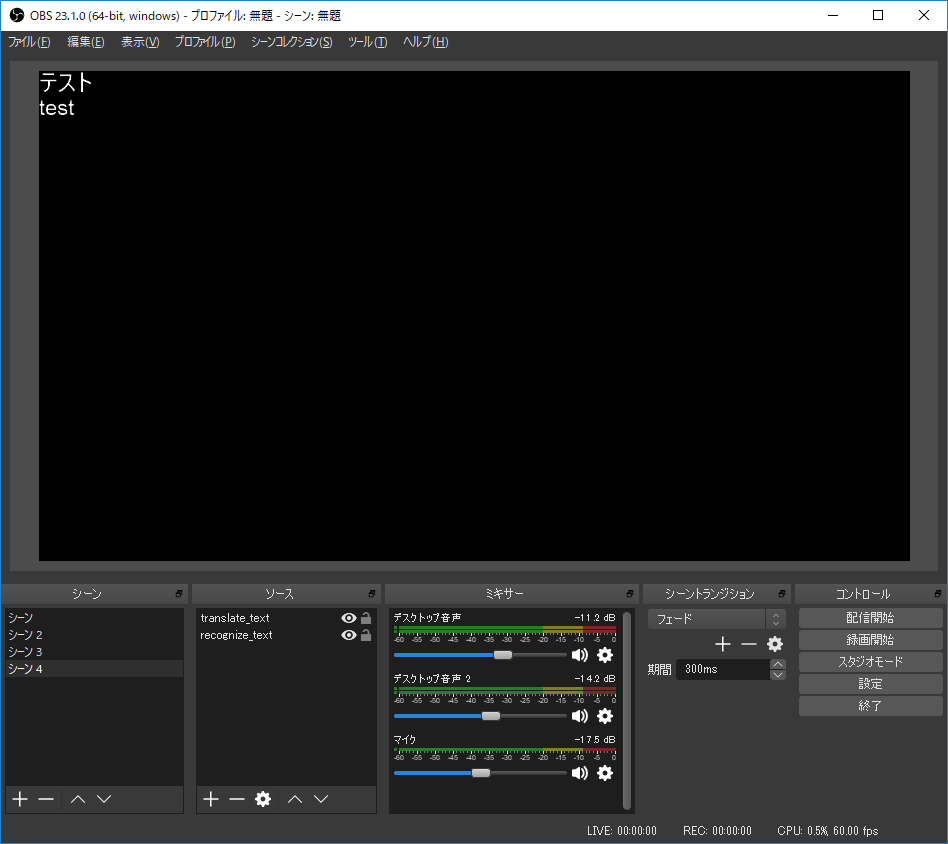
ソースに「テキスト(GDI+)」を新規で2つ追加し、名前をそれぞれ「recognize_text」「translate_text」にする。 前者に音声認識された文字列、後者に翻訳された文字列が流れ込む。 これらの初期の中身は何でもよいが例えば「テスト」などと書いておいてスタイルを好みに変更する。

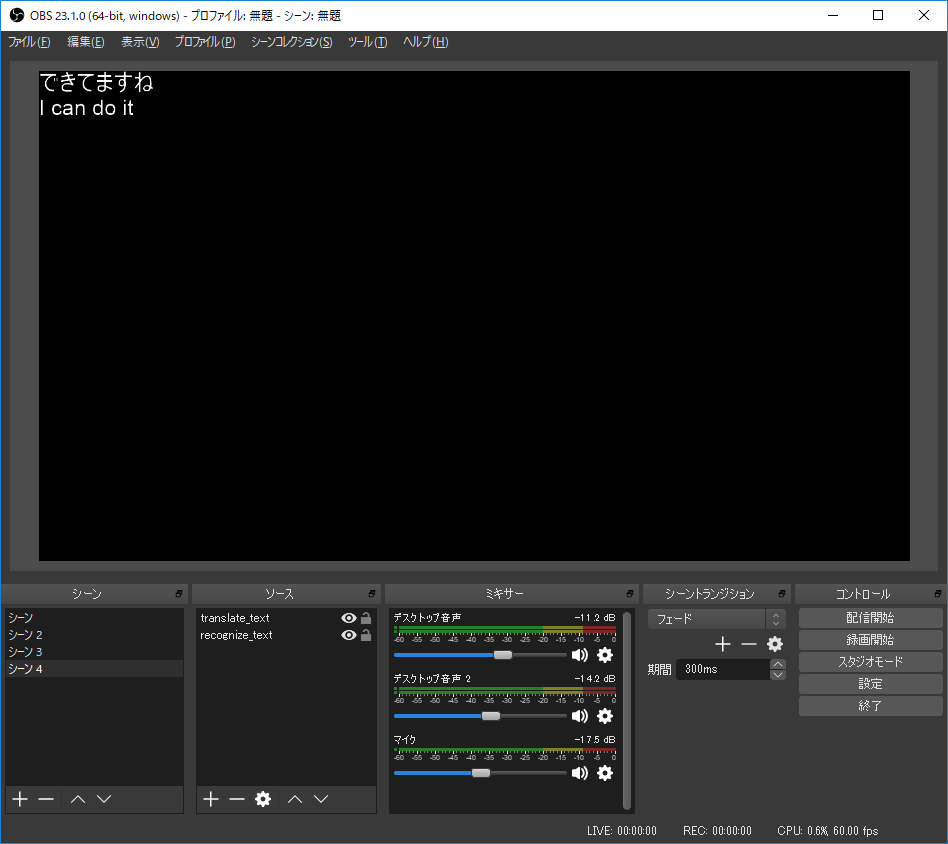
この状態でChromeで例のページを再読み込みし、startボタンを押してマイクを使えばOBS-Studioに音声認識と翻訳が流れ込むはず。